Why 0.1 + 0.2 ≠ 0.3: A Deep Dive into IEEE 754 and Floating-Point Arithmetic
You can find the Chinese version at 從 IEEE 754 標準來看為什麼浮點誤差是無法避免的
Introduction
When people first learn to code, they often encounter floating-point errors. If you haven't experienced this yet, you're very lucky!
For example, in Python, 0.1 + 0.2 does not equal 0.3, and 8.7 / 10 does not equal 0.87 but 0.869999… It's really strange.

However, this is not a bug or a flaw in Python. It's the result of how floating-point numbers are calculated, and this happens in other languages like Node.js too.

How Computers Store Integers
Before discussing floating-point errors, let's look at how computers represent integers using binary (0s and 1s). For instance, 101 in binary represents 2² + 2⁰ = 5, and 1010 represents 2³ + 2¹ = 10.

A 32-bit unsigned integer can hold 32 bits, so the smallest value is 0000...0000 (0), and the largest is 1111...1111, which is 2³¹ + 2³⁰ + … + 2¹ + 2⁰ = 4294967295.
Each bit can be either 0 or 1, giving 2³² possible values. This means any value between 0 and 2³²-1 can be represented without error.
How about Floating-Point Numbers
While there are many integers between 0 and 2³²-1, their number is limited to 2³². Floating-point numbers are different. In the range of 1 to 10, there are only ten integers but an infinite number of floating-point numbers like 5.1, 5.11, 5.111, etc.
Since a 32-bit space has only 2³² possibilities, fitting all floating-point numbers into this space requires a standard representation, which is where IEEE 754 comes in.
IEEE 754 Standard
IEEE 754 defines how to represent single (32-bit), double (64-bit), and special values (infinity, NaN) for floating-point numbers.
Normalization
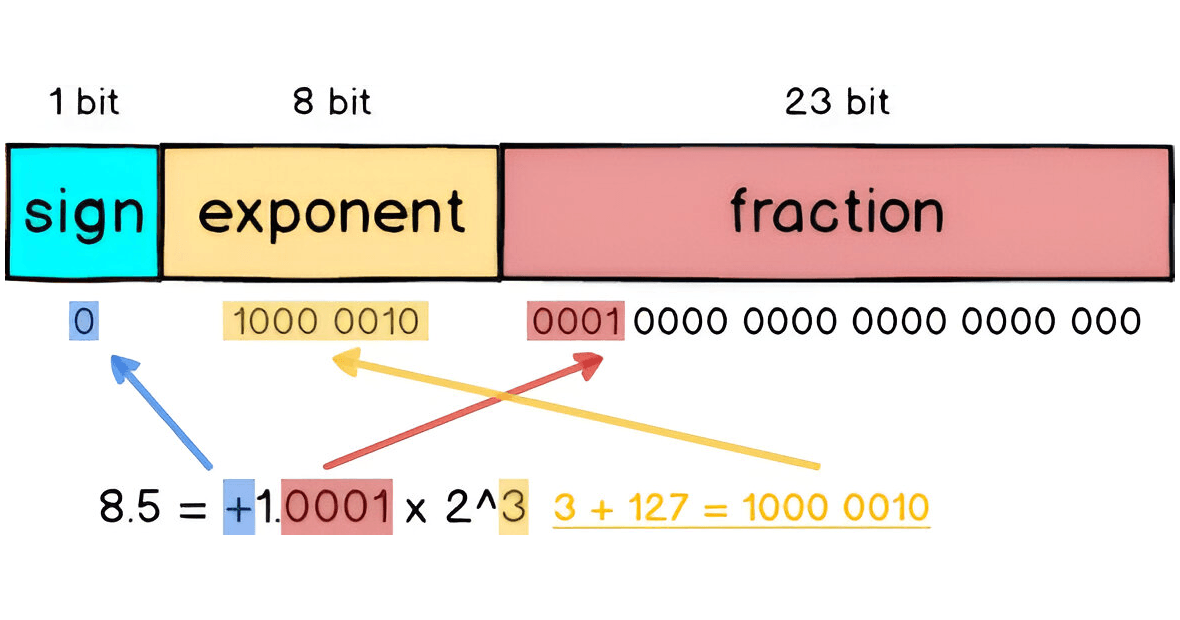
For example, to convert 8.5 to IEEE 754 format, you normalize it by breaking it into 8 + 0.5, which is 2³ + 1/2¹. In binary, this is 1000.1, or 1.0001 x 2³, similar to scientific notation in base 10.
Single Precision Floating-Point
In IEEE 754, a 32-bit floating-point number has three parts: sign, exponent, and fraction, adding up to 32 bits.

Sign: The leftmost bit indicates the sign (0 for positive, 1 for negative).
Exponent: The next 8 bits represent the exponent in a biased format (value + 127).
Fraction: The last 23 bits represent the fractional part (after the decimal point).
For example, 8.5 in 32-bit format is represented as:

When is it Inaccurate?
The example of 8.5 can be precisely represented as 2³ + 1/2¹ because both 8 and 0.5 are powers of 2, without precision loss.
However, for 8.9, which cannot be exactly represented as a sum of powers of 2, it must be approximated, resulting in small errors. You can explore these errors using the IEEE-754 Floating Point Converter.
Double Precision Floating-Point
To reduce errors, IEEE 754 also defines a 64-bit representation, doubling the size of the fraction part from 23 to 52 bits, thereby increasing precision.

For instance, while 8.9 still can't be perfectly represented, the error is much smaller in 64-bit format compared to 32-bit.

In Python, 1.0 and 0.999...999 are considered equal, as are 123 and 122.999...999, because their difference is too small to be represented in the fraction part.

Solutions
Since floating-point errors are unavoidable, here are two common ways to handle them:
Set a Maximum Allowable Error (epsilon)
Some languages provide an epsilon value to determine if a result is within an acceptable error range. In Python, epsilon is about 2.2e-16.

You can rewrite 0.1 + 0.2 == 0.3 as abs(0.1 + 0.2 - 0.3) <= epsilon to avoid errors in calculations.
Use Decimal Calculations
To avoid conversion errors between decimal and binary, use decimal calculations directly. Python's decimal module can handle this, performing exact decimal arithmetic.

While using decimal arithmetic eliminates floating-point errors, it is slower because it simulates decimal operations on the CPU, which natively uses binary.
Conclusion
Floating-point errors are unavoidable, but understanding IEEE 754 can help you manage them. Knowing the format's details can be interesting and useful, allowing you to explain why these errors occur confidently.