Sustain Your Data: A Practical Guide to Using Docker Volumes
You can find the Chinese version at Docker 實戰:使用 Volume 保存容器內的數據.
This is the third article in the Docker Series. If you haven't read the previous article, "Pushing Your Docker Images to Docker Hub: A Step-by-Step Guide", I recommend taking a look at it first.
As I mentioned before, each container operates in isolation. This means that if we need to upgrade the version of MySQL and decide to shut down the running mysql:5.5 container to start a new mysql:5.7 container, the data stored in the database would be lost. To address this issue, we can utilize volumes to ensure data persistence.
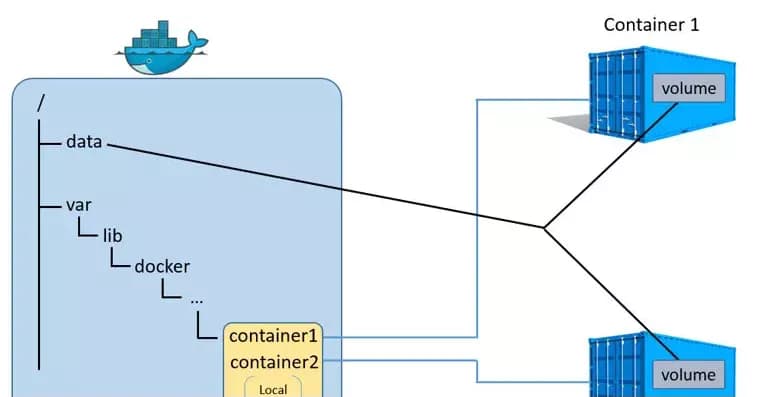
Basically, Volume is utilized to store data within containers. Let's take a look at the following diagram provided.
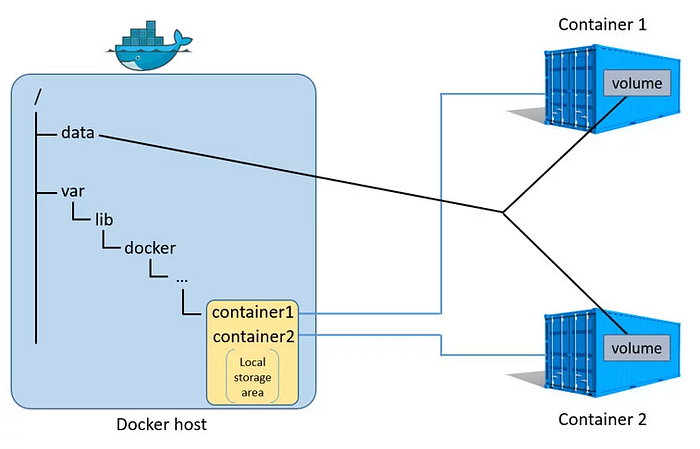
When you use a volume, Docker creates a local storage area on your machine, usually under /var, and establishes a connection between this folder and a specific folder inside the container. As they are connected, any changes made to the folder within the container will reflect in the local folder. Importantly, even if the container is deleted, the data remains intact in the volume. This allows us to preserve the container's data.
How to use named volumn
Step 1 - Creating a named volume
We first create a volume called "db-data". After completion, you will see an additional volume. Docker has now added a folder on your machine for the volume.
docker volume create --name db-data
docker volume ls

Step 2 - Using the volume
In this example, we are assigning the db-data volume to the /db/data location within the container. Alternatively, you can substitute it with the path where your database stores data. Let's give it a try:
Initially, confirm that there are no files in /db/data.
Then, create a file named "file" inside the container.
Finally, check if the file exists.
docker run -v db-data:/db/data -it ubuntu ls -la /db/data
docker run -v db-data:/db/data -it ubuntu touch /db/data/file
docker run -v db-data:/db/data -it ubuntu ls -la /db/data
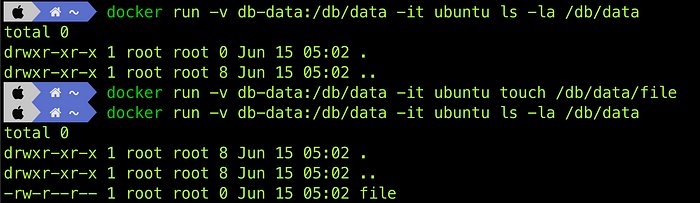
It's worth noting that these three commands are executed in different containers. This proves that even when a container is stopped, the data is still preserved in the volume, and the next container can successfully access the data left by the previous container.
Host Volume
The previous approach, where you create a volume before using it, is called a Named Volume. Now, let's introduce another approach called Host Volume, which directly connects a specific folder on your machine with a folder inside the container. Let's see a demo:
Check that there is no package.json inside
~/appon local machine.Connect the
~/appfolder on your machine with the/appfolder inside the container. Then, run npm init inside the container.Afterward, check if package.json has been created on your machine.
ls -la app
docker run -v ~/app:/app --workdir /app node:slim npm init -y
ls -la app

In the above example, package.json is actually generated inside the container. With volumes, you can avoid installing npm but still run npm init. Similarly, you can compile C++ source code without installing g++, develop Java programs without installing JDK, and even use MongoDB without installing it directly on your machine. With just Docker installed, the possibilities are endless! 🎉🎉
Conclusion
This article covered two types of volumes. I hope you have gained a good understanding. If you want to explore further, you can refer to the official documentation. Volumes will become a common practice in the upcoming chapters as we focus on data persistence.
In the next article, we will discuss how to split an application into multiple containers and have them work together to compose your application. If you're interested, feel free to follow along. Thank you!